Serverless Relational Showdown
Performance benchmarks of the various ways to use a relational database with AWS Lambda
A big gap in full-stack serverless development is how relational databases fit into the picture. I typically recommend looking at serverless native databases like DynamoDB or Fauna however they do not work for all preferences or workloads.
Talking to our community at ServerlessStack there's a huge appetite for deploying relational databases in a serverless environment. We decided to dig into the various ways to do this and identified the three most accessible options to run benchmarks against.
The Options
Amazon Aurora Serverless
This is Amazon's offering for a serverless relational database, either MySQL or Postgres. They manage the scaling of it up and down along with your traffic. This benchmark uses Postgres and connects to it through a pg connection inside a VPC.
Amazon Aurora Serverless with Data API
The issue with using the normal Aurora Serverless is the Postgres connection model was not meant for the serverless model. It was designed for a few long-lived processes that maintain a connection pool as opposed to potentially thousands of short-lived Lambda requests.
AWS created Data API to solve that problem. It exposes your RDS cluster as an HTTP API that can be called by your lambdas with high concurrency and AWS will manage the underlying connections. It has different performance characteristics so we wanted to benchmark.
Planetscale
Planetscale is a newer entrant in the managed relational database space. They offer a fully serverless MySQL offering built on top of Vitess and specifically support serverless workloads. I'm a huge personal fan so was excited to include it in the benchmark.
The Methodology
To connect to these various databases I am using the incredible library by Sami Koskimäki called Kysely. It offers a typesafe interface to both Postgres and MySQL and we're working on adding Data API support
The actual benchmark is simple, two different tasks were run:
1. 100 inserts started every second for 60 seconds
2. 100 reads started every second for 60 seconds
In the spirit of serverless this was coordinated using AWS serverless technologies:
1. An initial scheduling lambda is invoked, ticking every 1 second and starting a step function execution.
2. The step function uses the Map state to start 100 tasks in parallel to perform work against the database.
3. The final step aggregates the results and writes a file to S3
4. Once all the tasks were complete, Amazon Athena was used to extract the relevant data out into a final csv file.
Amazon Aurora Serverless Results
Read
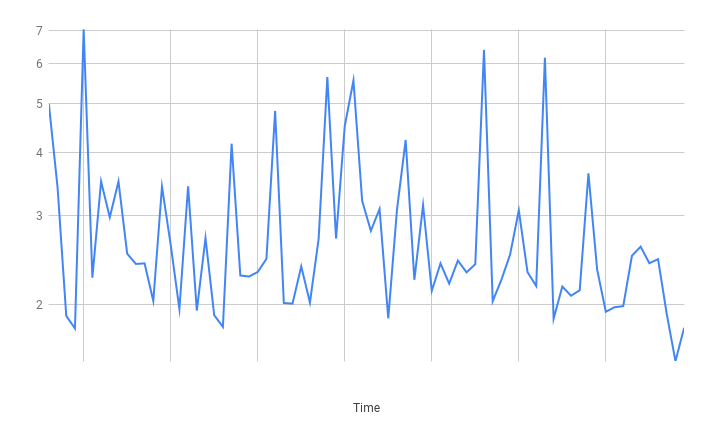
Insert
Summary
While reads were pretty fast and stable, you can see the inserts were less reliable. Because the writes took longer, there was more contention for the limited connection pool which created the spikes. At a higher scale this would start to look a bit worse.
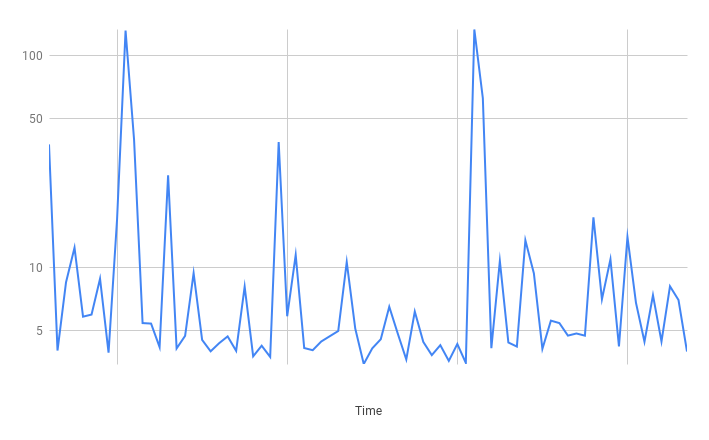
Data API Results
Read
Insert
Summary
Definitely slower than using a normal Postgres connection but it was also less spiky. I also noted in RDS metrics that the connections weren't maxed out so the pooling AWS is doing under the hood is more performant.
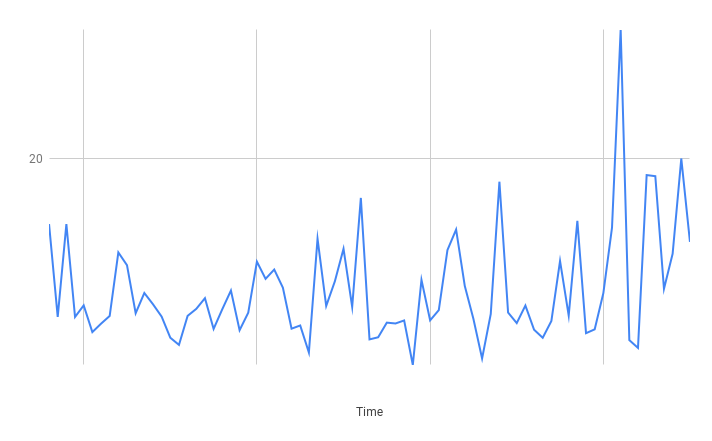
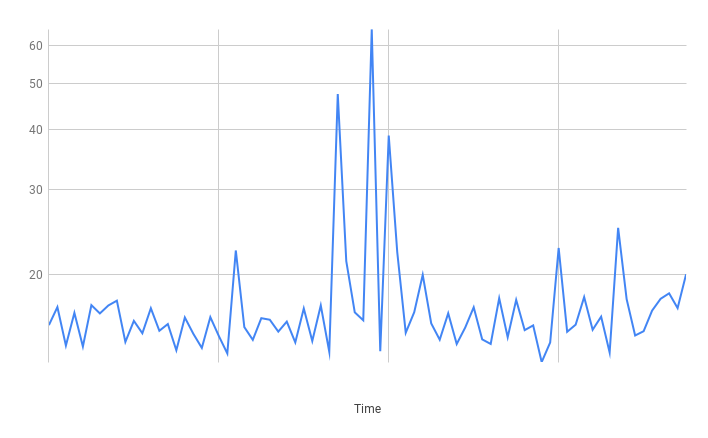
Planetscale Results
Read
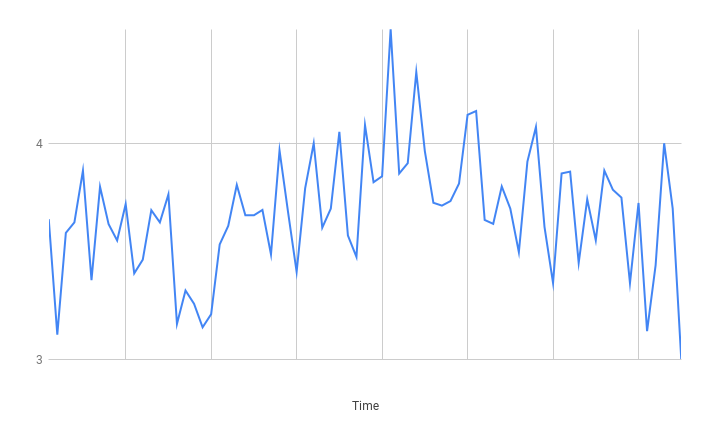
Insert
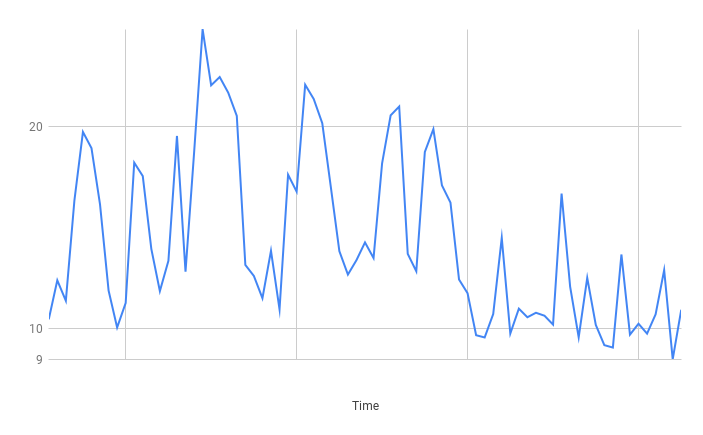
Summary
Really great results! Fairly decent latency on average and the spikes were not excessive.
The Conclusion
The good news is all the solutions are "fast enough." None of these feel too slow to use and unless you're optimizing for absolute speed they're all viable options.
That said, I'd personally pick Planetscale in this situation. Although it is a service outside of AWS it provides pretty good performance while being a low-touch managed service that deals well with serverless workloads.
Even though Data API performed worse, I'd probably stick to it if using Amazon Aurora. It's worth avoiding the connection hassles but I should probably benchmark Amazon Aurora Data Proxy in the future.
